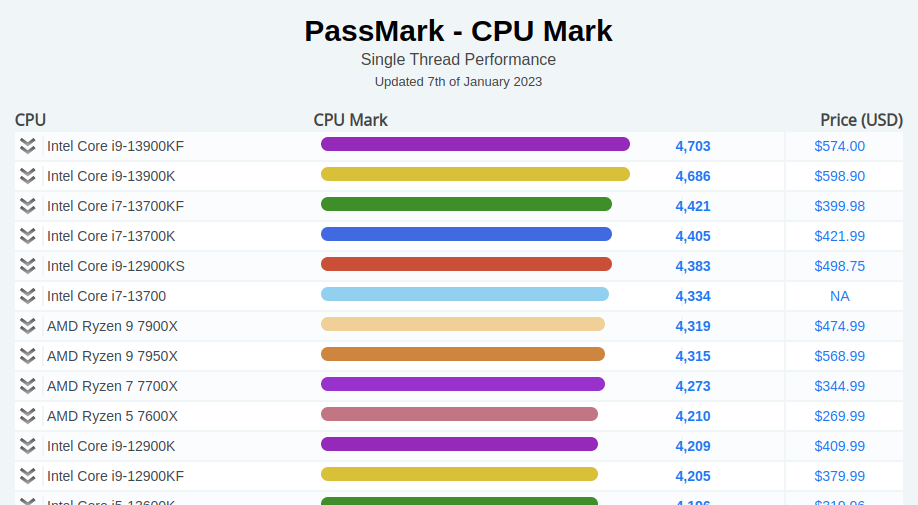
I have a dozen or so Raspberry Pis on my network that are used as routers, environmental sensors, looking glasses, and lab devices. They vary in models but I perform periodic upgrades to keep them running, which some have been for over 10 years now. I’ve recently realized I should be using SD cards with higher write counts on the RPis that run SmokePing so those are getting upgraded with priority. Many of these RPis are remote and headless so performing upgrades can be tricky. I’ve bricked one or two of them over the years and the fix was usually simple (OpenVPN / WireGuard issues or software bugs) but I’ve come across one recently that I can’t make heads or tails on!
I visited my parents in NJ last weekend and did a replace & clone of the SD cards in one of their RPis (a 3 B unit) that acts as a router on a stick (two VLAN-tagged interfaces running off eth0). The clone worked fine and I decided to do some upgrades before heading back to VA. I upgraded *udev*, *dbus*, *systemd*, and *raspberry*, which usually pulls in all the packages that typically require or recommend a reboot, which I figured I should do when I’m local. I track the equivalent Debian testing release on Raspbian / Raspberry Pi OS, which is currently bookworm. Unfortunately, this appeared to brick the box upon reboot. However, what was weird is that networking came up about 2 minutes after the reboot, which is very slow, but that’s it. SSH never started and neither did FRR (Free Range Routing, which starts OSPFv2, OSPFv3, and BGP) or the DHCP relay so while I could ping the interfaces the box failed to perform its most basic function. It seems I had a problem.
I connected the RPi to a TV and USB keyboard to debug further and found that some (actually all, I’d find out later) block devices were not being registered correctly with udev and causing systemd to drop to a emergency mode:
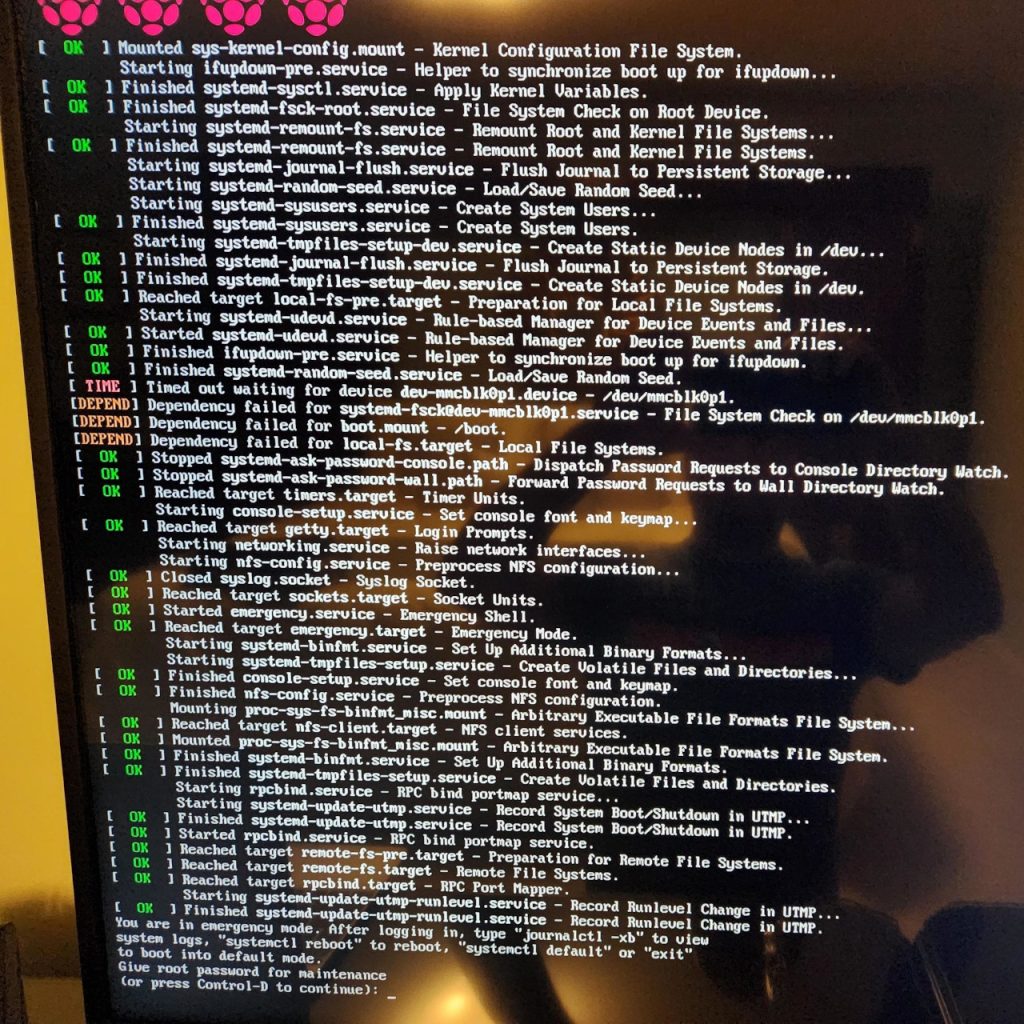
At first I thought that fsck was just taking awhile and needed more time so I added x-systemd.device-timeout=300s to /etc/fstab for both of the device nodes, /dev/mmcblk0p1 (boot) and /dev/mmcblk0p2 (root). Both are specified as raw device nodes and not UUIDs in my /etc/fstab file, which seems alright for now but probably something I should change in the future in case device nodes start moving around or getting renamed. I had to make this change by connecting the SD card to another Linux box in the house and mounting the filesystem.
This didn’t do anything. I changed the timeout a few more times and eventually gave up on this approach.
This is where things get annoying. I also tried to hit Control-D as specified but that just resulted in it sitting there for 90 seconds and returning to the emergency mode with the same prompt. I also tried to enter my root password (yes, it’s set!) but it wouldn’t take the password. I verified the password hash on another working RPi and could su to root just fine with the password.
So, I had no way of getting this RPi booted, using hacks or otherwise. The Raspberry Pi bootloader isn’t like GRUB and doesn’t have an interactive menu where one can play with the kernel command line options on the fly. It literally has no menu or interface and just boots one of the /boot/kernel*.img files, depending on the platform. If the boot fails, the RPi will just hang and display a color wheel on the screen. I thought about editing /boot/cmdline.txt and adding init=/bin/sh to the command line but I figured that would just bypass the problem and not allow me to actually figure out what was going on.
Short on time, I re-cloned the SD card from the original (unaltered) image I had saved on another machine (yes, I thought ahead!) and got the router back up & running without doing any upgrades.
After I returned home I re-created the setup with a spare RPi 3 B+ (similar hardware, although I found that a 1 B exhibited the problem too) and the original SD card image. Instead of upgrading all the reboot-required packages at once I did a few at a time. I started with *udev* and this triggered the issue. Here’s the exact upgrade path:
The following additional packages will be installed:
The following additional packages will be installed:
libblkid1
The following packages will be upgraded:
libblkid1 libudev1 udev
3 upgraded, 0 newly installed, 0 to remove and 491 not upgraded.
Need to get 1,789 kB of archives.
After this operation, 1,041 kB of additional disk space will be used.
Do you want to continue? [Y/n]
Get:1 http://mirror.umd.edu/raspbian/raspbian testing/main armhf libblkid1 armhf 2.38.1-5 [131 kB]
Get:2 http://raspbian.raspberrypi.org/raspbian testing/main armhf udev armhf 252.6-1+rpi1 [1,559 kB]
Get:3 http://raspbian.raspberrypi.org/raspbian testing/main armhf libudev1 armhf 252.6-1+rpi1 [99.1 kB]
Fetched 1,789 kB in 2s (1,137 kB/s)
(Reading database ... 59747 files and directories currently installed.)
Preparing to unpack .../libblkid1_2.38.1-5_armhf.deb ...
Unpacking libblkid1:armhf (2.38.1-5) over (2.36-3) ...
Setting up libblkid1:armhf (2.38.1-5) ...
(Reading database ... 59748 files and directories currently installed.)
Preparing to unpack .../udev_252.6-1+rpi1_armhf.deb ...
Unpacking udev (252.6-1+rpi1) over (247.2-5+rpi1) ...
Preparing to unpack .../libudev1_252.6-1+rpi1_armhf.deb ...
Unpacking libudev1:armhf (252.6-1+rpi1) over (247.2-5+rpi1) ...
Setting up libudev1:armhf (252.6-1+rpi1) ...
Setting up udev (252.6-1+rpi1) ...
Processing triggers for libc-bin (2.36-8+rpi1) ...
Processing triggers for man-db (2.9.3-2) ...
Processing triggers for initramfs-tools (0.139) ...I was able to view system.journal with journalctl --file on another machine to look at the logs and found some interesting stuff. Mainly, it looks like udev is running into errors with a rule specifying ID_SEAT for every single device node on the machine:
Apr 21 11:45:20 mercuryold systemd-udevd[159]: Using default interface naming scheme 'v252'.
Apr 21 11:45:20 mercuryold systemd[1]: Started systemd-udevd.service - Rule-based Manager for Device Events and Files.
Apr 21 11:45:20 mercuryold (udev-worker)[160]: vcs2: /usr/lib/udev/rules.d/73-seat-late.rules:13 Failed to import properties 'ID_SEAT' from parent: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[160]: vcs2: Failed to process device, ignoring: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[161]: vcsu2: /usr/lib/udev/rules.d/73-seat-late.rules:13 Failed to import properties 'ID_SEAT' from parent: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[161]: vcsu2: Failed to process device, ignoring: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[162]: vcsa2: /usr/lib/udev/rules.d/73-seat-late.rules:13 Failed to import properties 'ID_SEAT' from parent: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[162]: vcsa2: Failed to process device, ignoring: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[161]: vcsa3: /usr/lib/udev/rules.d/73-seat-late.rules:13 Failed to import properties 'ID_SEAT' from parent: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[161]: vcsa3: Failed to process device, ignoring: Operation not permitted
[...]mmcblk0 and friends are included here:
Apr 21 11:45:20 mercuryold (udev-worker)[165]: mmcblk0: /usr/lib/udev/rules.d/73-seat-late.rules:13 Failed to import properties 'ID_SEAT' from parent: Operation not permitted
Apr 21 11:45:20 mercuryold (udev-worker)[165]: mmcblk0: Failed to process device, ignoring: Operation not permittedAnd then, of course, this is what makes systemd actually unhappy:
Apr 21 11:48:46 mercuryold systemd[1]: dev-mmcblk0p1.device: Job dev-mmcblk0p1.device/start timed out.
Apr 21 11:48:46 mercuryold systemd[1]: Timed out waiting for device dev-mmcblk0p1.device - /dev/mmcblk0p1.
Apr 21 11:48:46 mercuryold systemd[1]: Dependency failed for boot.mount - /boot.
Apr 21 11:48:46 mercuryold systemd[1]: Dependency failed for local-fs.target - Local File Systems.So, something was busted in udev. I took a peek at 73-seat-late.rules and it’s pretty stock and the same on all of my systems:
# SPDX-License-Identifier: LGPL-2.1-or-later
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
ACTION=="remove", GOTO="seat_late_end"
ENV{ID_SEAT}=="", ENV{ID_AUTOSEAT}=="1", ENV{ID_FOR_SEAT}!="", ENV{ID_SEAT}="seat-$env{ID_FOR_SEAT}"
ENV{ID_SEAT}=="", IMPORT{parent}="ID_SEAT"
ENV{ID_SEAT}!="", TAG+="$env{ID_SEAT}"
TAG=="uaccess", ENV{MAJOR}!="", RUN{builtin}+="uaccess"
LABEL="seat_late_end"Line 13 is:
ENV{ID_SEAT}=="", IMPORT{parent}="ID_SEAT"I did some searching and didn’t find any hits on any search engines that references this type of error or failure. What’s worse is that I poked the udev versions on some of my other RPis and it’s the same as the supposed broken version that I upgraded to, 252.6-1+rpi1. That version is also the most current version in Debian as well (minus experimental).
I then tried to see if I could get a shell on the machine somehow to troubleshoot it in the bad state. I tried to get sshd to start earlier in the boot process but after messing with the dependency directives in ssh.service and sshd.service a few times and that didn’t change anything, I gave up on it for now.
(destiny:19:23:EDT)% head ./system/sshd.service
[Unit]
Description=OpenBSD Secure Shell server
Documentation=man:sshd(8) man:sshd_config(5)
#After=network.target auditd.service
After=systemd-remount-fs.service
ConditionPathExists=!/etc/ssh/sshd_not_to_be_run
[Service]
EnvironmentFile=-/etc/default/ssh
ExecStartPre=/usr/sbin/sshd -t(the above didn’t so squat but I’m probably doing it wrong or I need to manually run whatever systemd edit does usually after one changes a unit file)
I’m at a stopping point for this now. I suppose the next thing I might try is re-cloning the SD card again and doing a full upgrade instead of just udev or just reboot-required packages to see if there’s some missed dependency somewhere that doesn’t result in the breakage, but that’s a long shot especially since any udev dependency would either be kernel or systemd-related, and I upgraded those and it didn’t help. I also need to figure out why entering my root password doesn’t get me into the system—that’s actually more troubling than the other issue.
For those who are reading this post, have you seen this before or have any suggestions to try?
Update on 2023-05-01
I ended up figuring this out last week, mostly. I still don’t know why just upgrading the udev package bricked the RPi but I do know that the raspberrypi-kernel package will fail to install due to insufficient disk space but not return an error code to dpkg, so if someone isn’t watching the terminal closely, this could be missed.
This was part of my problem. /boot was only 60 MiB on this machine (it was an older image, my newer RPi installs have a 253 MiB /boot) and the kernel install failed but the modules in /lib/modules succeeded. The existing kernel image was untouched but its modules were no longer present. So, upon reboot, lots of things didn’t work at all since there were no loadable modules.
To avoid the nastiness of resizing /boot, I ended up just unmounting /boot, mounting it at /realboot, rsync’ing contents over to /boot (which is actually temporarily part of /), doing the kernel upgrade, then rsync’ing /boot back to /realboot, and unmounting & remounting things again. This only works because during the install of raspberrypi-kernel, you need much more than 60 MiB in /boot, but when the upgrade is finished, 60 MiB is sufficient (barely):
Filesystem Size Used Avail Use% Mounted on
/dev/mmcblk0p1 60M 56M 4.8M 93% /bootThe fix here is to not upgrade udev by itself (I only did this as a test) but always upgrade that and the kernel at the same time. So, if I had done the /boot trick originally, I wouldn’t have had any issues.