A couple weeks ago I wrote a blog on T-Mobile Home Internet and I felt like I needed to post a quick follow-up.
Overall, the service works great. I have the “backup Internet” plan that includes 130GiB of data, which I’m prolly never going to get close to using. I ended up getting this setup at the right time since we took a trip to Finland for a week and our area had a power outage that nuked the UPS that happened to be connected to my Verizon Fios connection & Linux router and since it went into overload it never restored. So, for 2.5 days half (my home network became unfortunately bifurcated) of my home was able to stay online through the T-Mobile connection, enough for me to peek at some of the security cameras and SSH in to check on a few things.
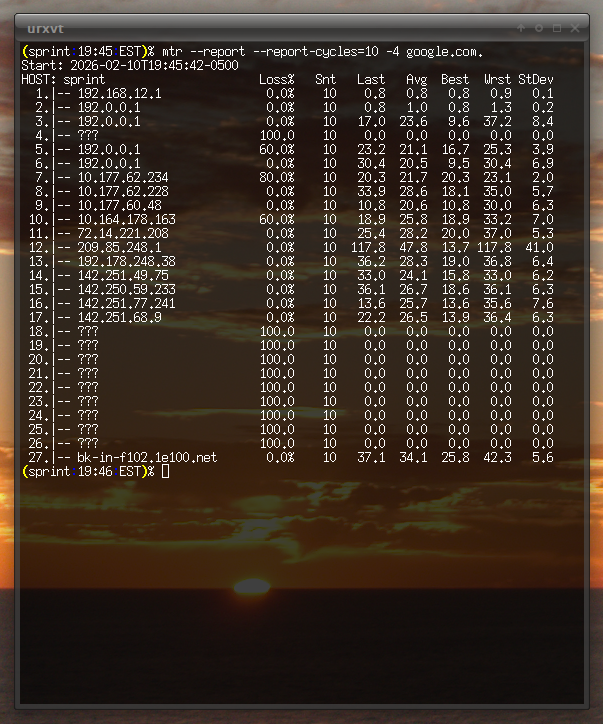
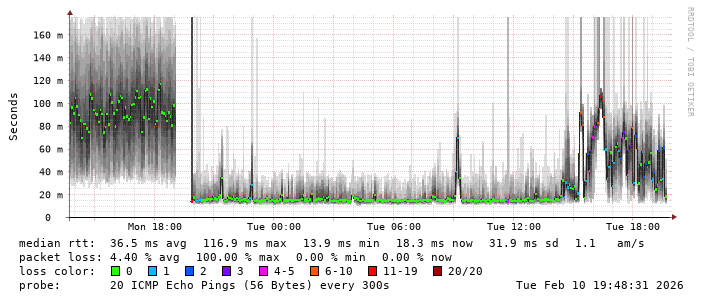
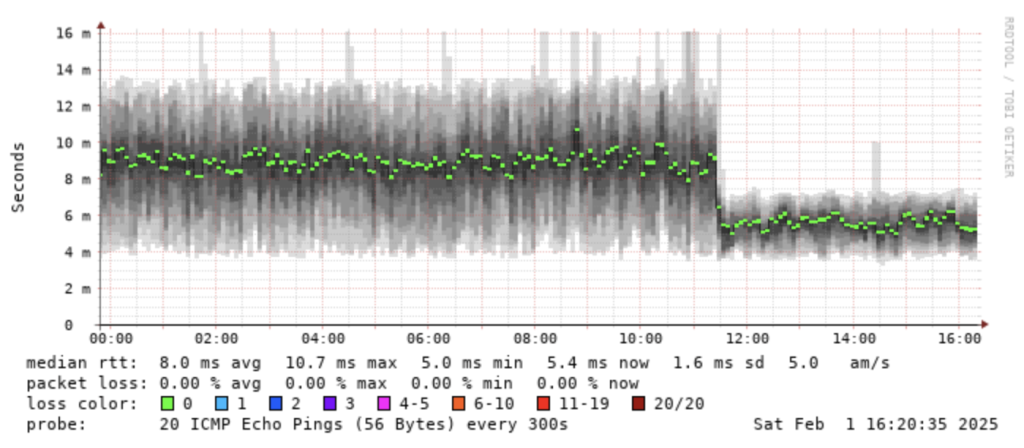
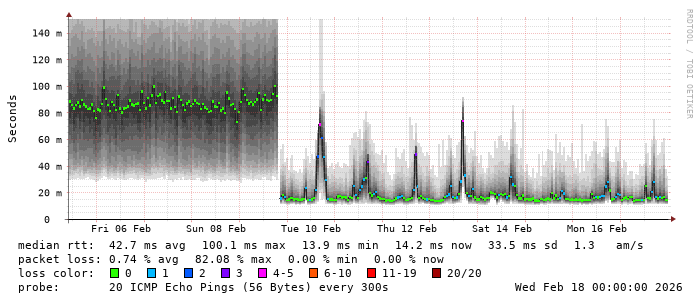
The latency seems to spike a bit during the early evening hours every day (mostly weekdays). Sometimes it results in a bunch of packet loss. I’m guessing this is due to folks coming home from work and using the network before their phones connect to Wi-Fi. Maybe there’s another explanation, too. However, it’s all still much lower than the Verizon Wireless connection and it didn’t seem to impact any speed (although the VZW connection never showed any obvious latency variation due to time of day).
As it has been mentioned in other forums, MTU is lower on T-Mobile compared to other carriers like VZW. Actually, I’m pretty sure it’s lower than 1500 bytes on VZW as well but they might employ link-level fragmentation.
The problem with the MTU on T-Mobile is that PMTUD reports the wrong value (shocker, PMTUD broken, I know). Here’s a tracepath:
(sprint:10:16:EST)% tracepath -p 33434 -4 gravity
1?: [LOCALHOST] pmtu 1500
1: 192.168.12.1 0.871ms
1: 192.168.12.1 0.779ms
2: 192.0.0.1 1.239ms
3: 192.0.0.1 1.491ms pmtu 1480
3: no reply
4: no reply
5: no reply
6: no reply
7: no reply
[...snip...]
And tcpdump:
(sprint:10:15:EST)% sudo tcpdump -v -i enp5s6 -n "((portrange 33434-33534 and proto 17) and host 18.100.109.137) or proto 1"
tcpdump: listening on enp5s6, link-type EN10MB (Ethernet), snapshot length 262144 bytes
10:16:02.471423 IP (tos 0x0, ttl 1, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33434: UDP, length 1472
10:16:02.472160 IP (tos 0xc0, ttl 64, id 9523, offset 0, flags [none], proto ICMP (1), length 576)
192.168.12.1 > 192.168.12.102: ICMP time exceeded in-transit, length 556
IP (tos 0x0, ttl 1, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33434: UDP, length 1472
10:16:02.473337 IP (tos 0x0, ttl 1, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33435: UDP, length 1472
10:16:02.473962 IP (tos 0xc0, ttl 64, id 9524, offset 0, flags [none], proto ICMP (1), length 576)
192.168.12.1 > 192.168.12.102: ICMP time exceeded in-transit, length 556
IP (tos 0x0, ttl 1, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33435: UDP, length 1472
10:16:02.475246 IP (tos 0x0, ttl 2, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33436: UDP, length 1472
10:16:02.476354 IP (tos 0x0, ttl 63, id 29150, offset 0, flags [DF], proto ICMP (1), length 1240)
192.0.0.1 > 192.168.12.102: ICMP time exceeded in-transit, length 1220
IP (tos 0x0, ttl 1, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33436: UDP, length 1472
10:16:02.477448 IP (tos 0x0, ttl 3, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33437: UDP, length 1472
10:16:02.478408 IP (tos 0x0, ttl 63, id 29406, offset 0, flags [DF], proto ICMP (1), length 1240)
192.0.0.1 > 192.168.12.102: ICMP 18.100.109.137 unreachable - need to frag (mtu 1480), length 1220
IP (tos 0x0, ttl 2, id 0, offset 0, flags [DF], proto UDP (17), length 1500)
192.168.12.102.37692 > 18.100.109.137.33437: UDP, length 1472
10:16:02.479946 IP (tos 0x0, ttl 3, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33438: UDP, length 1452
10:16:03.481089 IP (tos 0x0, ttl 3, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33439: UDP, length 1452
10:16:04.481646 IP (tos 0x0, ttl 3, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33440: UDP, length 1452
10:16:05.482838 IP (tos 0x0, ttl 4, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33441: UDP, length 1452
10:16:06.483986 IP (tos 0x0, ttl 4, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33442: UDP, length 1452
10:16:07.485137 IP (tos 0x0, ttl 4, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33443: UDP, length 1452
10:16:08.485699 IP (tos 0x0, ttl 5, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33444: UDP, length 1452
10:16:09.486857 IP (tos 0x0, ttl 5, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33445: UDP, length 1452
10:16:10.488001 IP (tos 0x0, ttl 5, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33446: UDP, length 1452
10:16:11.489199 IP (tos 0x0, ttl 6, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33447: UDP, length 1452
10:16:12.489641 IP (tos 0x0, ttl 6, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33448: UDP, length 1452
10:16:13.490787 IP (tos 0x0, ttl 6, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33449: UDP, length 1452
10:16:14.491978 IP (tos 0x0, ttl 7, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33450: UDP, length 1452
10:16:15.493124 IP (tos 0x0, ttl 7, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33451: UDP, length 1452
10:16:16.493642 IP (tos 0x0, ttl 7, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33452: UDP, length 1452
10:16:17.494836 IP (tos 0x0, ttl 8, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33453: UDP, length 1452
10:16:18.495978 IP (tos 0x0, ttl 8, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33454: UDP, length 1452
10:16:19.497118 IP (tos 0x0, ttl 8, id 0, offset 0, flags [DF], proto UDP (17), length 1480)
192.168.12.102.37692 > 18.100.109.137.33455: UDP, length 1452
[...snip...]
The 192.0.0.1 hop (internal to the router itself, likely CLAT+464XLAT) advertised path MTU of 1480, but this is clearly wrong. The rest of the traceroute times out for every subsequent hop because tracepath believes 1480 is correct (you’ll see it lowers the UDP size fo 1452) and the probes never make it past the T-Mobile router to generate a TTL exceeded response.
I did some playing and found that on my connection the MTU is actually 1436:
(sprint:10:21:EST)% ping4 -c 4 -M do -s 1409 gravity
PING gravity (18.100.109.137) 1409(1437) bytes of data.
--- gravity ping statistics ---
4 packets transmitted, 0 received, 100% packet loss, time 3067ms
(sprint:10:21:EST)% ping4 -c 4 -M do -s 1408 gravity
PING gravity (18.100.109.137) 1408(1436) bytes of data.
1416 bytes from ec2-18-100-109-137.eu-south-2.compute.amazonaws.com (18.100.109.137): icmp_seq=1 ttl=43 time=125 ms
1416 bytes from ec2-18-100-109-137.eu-south-2.compute.amazonaws.com (18.100.109.137): icmp_seq=2 ttl=43 time=123 ms
1416 bytes from ec2-18-100-109-137.eu-south-2.compute.amazonaws.com (18.100.109.137): icmp_seq=3 ttl=43 time=122 ms
1416 bytes from ec2-18-100-109-137.eu-south-2.compute.amazonaws.com (18.100.109.137): icmp_seq=4 ttl=43 time=145 ms
--- gravity ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 121.856/128.792/144.883/9.373 ms
I don’t think most folks will notice this because modern stacks assume PMTUD is broken and things like HTTP/3 and QUIC (both UDP-based) implement their own path MTU discovery at the application layer. Also, many CDNs use a lower MTU by default to work around brokenness like this.
However, I’m surprised T-Mobile has this problem in 2026.