tl;dr Yes, SIP INVITEs are blocked via what seems to be a packet size filter but some things are inconsistent.
Back in early 2020 I switched from Comcast Business to CenturyLink DSL for my main Internet connection. I still have Xfinity since my wife uses it for TV and her package comes with a 300 Mbps plan (that use for VPNs and some fun downstream-only load-balancing.. but that’s another topic). Anyway, when I flipped Internet IPv4 access over to the DSL connection I noticed that my outbound SIP connections to Vitelity (via my Asterisk server) were failing and timing out. SIP REGISTERs were fine so I could still receive incoming calls. I did a 30 second debug with tcpdump, saw packets going out but nothing coming back in. PPPoE adds an 8 byte overhead and the packets going out were 1492 bytes so I figured they would fit and that CenturyLink was just blocking SIP because they are “The Phone Company” and probably wanted me to buy a land line or something. I internally advertised Vitelity’s block from the LXC instance attached to my Xfinity connection and called it a day.
I was chatting with folks at work this past week regarding this and it prompted me to dig a little deeper. What I observed in early 2020 didn’t paint the whole picture. The SIP INVITEs are being sent to outbound.vitelity.net, which has a few A RRs all out of the 64.2.142.0/24. The SIP packets themselves are huge, and even fragment on my local network since the total length of the first packet (including IP headers) is 1634 bytes. So, this means the SIP packets are being fragmented going out my Xfinity connection and still working fine:
(remus:19:27:PST)% sudo tcpdump -i enp3s0f1 -qvn net 64.2.142.0/24
tcpdump: listening on enp3s0f1, link-type EN10MB (Ethernet), capture size 262144 bytes
19:27:21.045354 IP (tos 0x0, ttl 62, id 34953, offset 0, flags [+], proto UDP (17), length 1500)
98.247.161.61.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1472
19:27:21.045360 IP (tos 0x0, ttl 62, id 34953, offset 1480, flags [none], proto UDP (17), length 180)
98.247.161.61 > 64.2.142.188: ip-proto-17
19:27:21.228064 IP (tos 0x20, ttl 48, id 51882, offset 0, flags [none], proto UDP (17), length 567)
64.2.142.188.5060 > 98.247.161.61.5060: UDP, length 539
19:27:21.228368 IP (tos 0x0, ttl 62, id 34986, offset 0, flags [none], proto UDP (17), length 452)
98.247.161.61.5060 > 64.2.142.188.5060: UDP, length 424
19:27:21.228593 IP (tos 0x0, ttl 62, id 34987, offset 0, flags [+], proto UDP (17), length 1500)
98.247.161.61.5060 > 64.2.142.188.5060: UDP, bad length 1824 > 1472
19:27:21.228598 IP (tos 0x0, ttl 62, id 34987, offset 1480, flags [none], proto UDP (17), length 372)
98.247.161.61 > 64.2.142.188: ip-proto-17
19:27:21.311301 IP (tos 0x20, ttl 48, id 51883, offset 0, flags [none], proto UDP (17), length 492)
64.2.142.188.5060 > 98.247.161.61.5060: UDP, length 464
19:27:23.510342 IP (tos 0x20, ttl 48, id 51885, offset 0, flags [none], proto UDP (17), length 882)
64.2.142.188.5060 > 98.247.161.61.5060: UDP, length 854
So, fragmentation and packet size may not be the problem. SIP packets halfway through the outgoing call setup are even larger, past 1800 bytes! Well, fragmentation usually stinks but it seems to work fine here.
First, why are these SIP packets so large? It looks like it’s because of the list of advertised available codecs. Here’s a full decode of the first message (my authentication data is temporarily scrambled, FWIW):
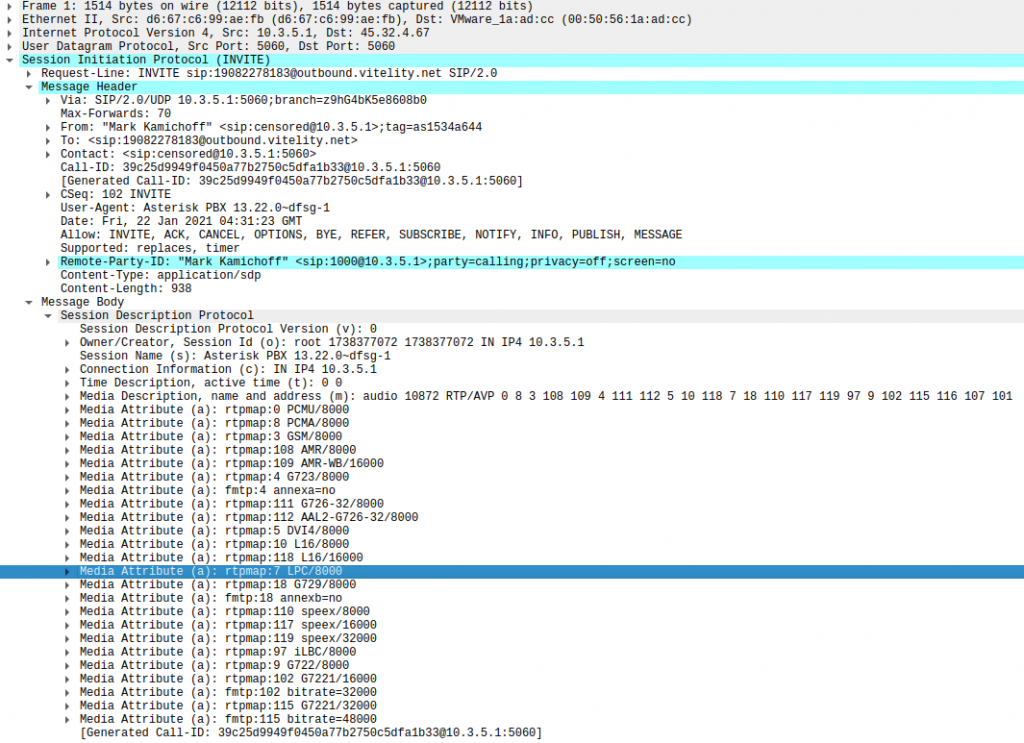
I could probably dust off my Asterisk configuration and figure out how to reduce the number of useless codecs that are advertised but since this works via my Xfinity connection I’m not going to focus on that.
Here’s what it looks like out my DSL connection:
(discovery:19:42:PST)% sudo tcpdump -i ppp0 -qvn net 64.2.142.0/24
tcpdump: listening on ppp0, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes
19:43:13.716582 IP (tos 0x0, ttl 61, id 27388, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1464
19:43:13.716624 IP (tos 0x0, ttl 61, id 27388, offset 1472, flags [none], proto UDP (17), length 188)
97.113.163.82 > 64.2.142.188: ip-proto-17
19:43:14.216162 IP (tos 0x0, ttl 61, id 27435, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1464
19:43:14.216200 IP (tos 0x0, ttl 61, id 27435, offset 1472, flags [none], proto UDP (17), length 188)
97.113.163.82 > 64.2.142.188: ip-proto-17
19:43:15.217157 IP (tos 0x0, ttl 61, id 27666, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1464
19:43:15.217197 IP (tos 0x0, ttl 61, id 27666, offset 1472, flags [none], proto UDP (17), length 188)
97.113.163.82 > 64.2.142.188: ip-proto-17
And, just as a sanity check, I see it out the physical Ethernet interface that the PPP daemon is using, too:
(discovery:19:43:PST)% sudo tcpdump -i eth1 -qvn
tcpdump: listening on eth1, link-type EN10MB (Ethernet), capture size 262144 bytes
19:43:13.716605 PPPoE [ses 0x9e8a] IP (tos 0x0, ttl 61, id 27388, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1464
19:43:13.716661 PPPoE [ses 0x9e8a] IP (tos 0x0, ttl 61, id 27388, offset 1472, flags [none], proto UDP (17), length 188)
97.113.163.82 > 64.2.142.188: ip-proto-17
19:43:14.216182 PPPoE [ses 0x9e8a] IP (tos 0x0, ttl 61, id 27435, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1464
19:43:14.216208 PPPoE [ses 0x9e8a] IP (tos 0x0, ttl 61, id 27435, offset 1472, flags [none], proto UDP (17), length 188)
97.113.163.82 > 64.2.142.188: ip-proto-17
19:43:15.217178 PPPoE [ses 0x9e8a] IP (tos 0x0, ttl 61, id 27666, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 64.2.142.188.5060: UDP, bad length 1632 > 1464
19:43:15.217204 PPPoE [ses 0x9e8a] IP (tos 0x0, ttl 61, id 27666, offset 1472, flags [none], proto UDP (17), length 188)
97.113.163.82 > 64.2.142.188: ip-proto-17
If you look at the packet lengths, the Linux LXC instance attached to my DSL line is re-fragmenting the packet that’s originally fragmented from my Asterisk server to something that will fit into 1492 MTU. It’s 1492+188 instead of 1500+180, now. Yes, fragmentation is working as expected even though it’s kinda horrid!
So, I was wondering how CenturyLink might be blocking the SIP traffic? Just blocking UDP/5060 traffic might be an easy choice, so I tested this using NetCat to a VM of mine, remembering to set both the source and destination ports to 5060 (discovery is the DSL LXC instance and dax is the remote VM):
(discovery:19:51:PST)% nc -u -p 5060 45.32.4.66 5060
Hi.
And this is seen on dax:
(dax:22:51:EST)% sudo tcpdump -qvi vtnet0 -n port 5060
tcpdump: listening on vtnet0, link-type EN10MB (Ethernet), capture size 262144 bytes
22:51:26.612983 IP (tos 0x0, ttl 57, id 30455, offset 0, flags [DF], proto UDP (17), length 32)
97.113.163.82.5060 > 45.32.4.66.5060: UDP, length 4
Okie doke. This is not the way they’re blocking it. How about large UDP packet sizes like the kind we saw with SIP and some fragmentation? For this we’ll use hping3:
(discovery:19:55:PST)% sudo hping3 -2 -s 5060 -p 5060 -d 1600 -c 2 45.32.4.66
HPING 45.32.4.66 (ppp0 45.32.4.66): udp mode set, 28 headers + 1600 data bytes
--- 45.32.4.66 hping statistic ---
2 packets transmitted, 0 packets received, 100% packet loss
round-trip min/avg/max = 0.0/0.0/0.0 ms
hping3 will automatically fragment if you specify a data size that results in the generated packet exceeding the interface MTU. 1,600 bytes does this for us.
But, I’m only seeing the fragments on my VM:
(dax:23:01:EST)% sudo tcpdump -qvi vtnet0 -n host 97.113.163.82
tcpdump: listening on vtnet0, link-type EN10MB (Ethernet), capture size 262144 bytes
23:01:39.219056 IP (tos 0x0, ttl 57, id 25, offset 1472, flags [none], proto UDP (17), length 156)
97.113.163.82 > 45.32.4.66: ip-proto-17
23:01:40.219297 IP (tos 0x0, ttl 57, id 25, offset 1472, flags [none], proto UDP (17), length 156)
97.113.163.82 > 45.32.4.66: ip-proto-17
Verifying that my LXC instance is actually sending the packets correctly, I tcpdump ppp0:
(discovery:20:01:PST)% sudo tcpdump -qv -i ppp0 -n host 45.32.4.66
tcpdump: listening on ppp0, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes
20:01:39.051291 IP (tos 0x0, ttl 64, id 25, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5060 > 45.32.4.66.5060: UDP, bad length 1600 > 1464
20:01:39.051362 IP (tos 0x0, ttl 64, id 25, offset 1472, flags [none], proto UDP (17), length 156)
97.113.163.82 > 45.32.4.66: ip-proto-17
20:01:40.051589 IP (tos 0x0, ttl 64, id 25, offset 0, flags [+], proto UDP (17), length 1492)
97.113.163.82.5061 > 45.32.4.66.5060: UDP, bad length 1600 > 1464
20:01:40.051620 IP (tos 0x0, ttl 64, id 25, offset 1472, flags [none], proto UDP (17), length 156)
97.113.163.82 > 45.32.4.66: ip-proto-17
Yep, this is fine. So, looks like CenturyLink is blocking huge packets. Just to round this out, I try without a fragmented packet:
(discovery:20:04:PST)% sudo hping3 -2 -s 5060 -p 5060 -d 1464 -c 2 45.32.4.66
HPING 45.32.4.66 (ppp0 45.32.4.66): udp mode set, 28 headers + 1464 data bytes
--- 45.32.4.66 hping statistic ---
2 packets transmitted, 0 packets received, 100% packet loss
round-trip min/avg/max = 0.0/0.0/0.0 ms
Nothing seen on the VM:
(dax:23:04:EST)% sudo tcpdump -qvi vtnet0 -n host 97.113.163.82
tcpdump: listening on vtnet0, link-type EN10MB (Ethernet), capture size 262144 bytes
Well, of course, I need to know, where are they blocking these packets and how large of a packet can get through? I started with one byte less than the full payload:
(discovery:20:06:PST)% sudo hping3 -2 -s 5060 -p 5060 -d 1463 -c 1 45.32.4.66
HPING 45.32.4.66 (ppp0 45.32.4.66): udp mode set, 28 headers + 1463 data bytes
--- 45.32.4.66 hping statistic ---
1 packets transmitted, 0 packets received, 100% packet loss
round-trip min/avg/max = 0.0/0.0/0.0 ms
Yep!
(dax:23:06:EST)% sudo tcpdump -qvi vtnet0 -n host 97.113.163.82
tcpdump: listening on vtnet0, link-type EN10MB (Ethernet), capture size 262144 bytes
23:06:32.247196 IP (tos 0x0, ttl 57, id 23545, offset 0, flags [none], proto UDP (17), length 1491)
97.113.163.82.5060 > 45.32.4.66.5060: UDP, length 1463
That’s the packet. So, now that that’s answered, where are they blocking it? We can use MTR for this. Here’s the same full UDP packet with both source and destination port of 5060:
(discovery:20:25:PST)% mtr --report --report-cycles=5 --report-wide -s 1492 -L 5060 -P 5060 -u 45.32.4.66
Start: 2021-01-23T20:25:10-0800
HOST: discovery Loss% Snt Last Avg Best Wrst StDev
(discovery:20:25:PST)%
Well, normally the first hop would be the BRAS in Tukwila, WA. We see nothing here. Let’s lower it back to 1491:
(discovery:20:28:PST)% mtr --report --report-cycles=5 --report-wide -s 1491 -L 5060 -P 5060 -u 45.32.4.66
Start: 2021-01-23T20:28:34-0800
HOST: discovery Loss% Snt Last Avg Best Wrst StDev
1.|-- tukw-dsl-gw75.tukw.qwest.net 0.0% 5 8.1 8.0 7.7 8.2 0.2
2.|-- 63-226-198-81.tukw.qwest.net 0.0% 5 32.4 24.2 8.3 43.9 14.0
3.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
4.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
5.|-- CHOOPA-LLC.ear3.NewYork1.Level3.net 0.0% 5 86.1 83.9 81.5 88.7 3.4
6.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
My VM filters UDP/5060 but we do see it in tcpdump and the traceroute does get through CenturyLink’s network. Looks like it’s the BRAS itself or something between that and me. But wait, as I was messing around I up-arrowed and I’m seeing 1492 being passed now too:
(discovery:20:30:PST)% mtr --report --report-cycles=5 --report-wide -s 1492 -L 5060 -P 5060 -u 45.32.4.66
Start: 2021-01-23T20:30:07-0800
HOST: discovery Loss% Snt Last Avg Best Wrst StDev
1.|-- tukw-dsl-gw75.tukw.qwest.net 0.0% 5 7.6 16.6 7.6 47.4 17.3
2.|-- tukw-agw1.inet.qwest.net 0.0% 5 7.9 11.6 7.8 26.2 8.2
3.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
4.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
5.|-- CHOOPA-LLC.ear3.NewYork1.Level3.net 0.0% 5 82.3 81.8 81.4 82.3 0.3
6.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
What the heck? A minute ago it was being blocked and now it’s going through? Yep, I just saw those full packets on my VM:
23:30:13.795238 IP (tos 0x0, ttl 9, id 26455, offset 0, flags [none], proto UDP (17), length 1492)
97.113.163.82.5060 > 45.32.4.66.5060: UDP, length 1464
23:30:13.854422 IP (tos 0x0, ttl 10, id 26465, offset 0, flags [none], proto UDP (17), length 1492)
97.113.163.82.5060 > 45.32.4.66.5060: UDP, length 1464
Huh? Everything was consistent up until now. I left it for a few minutes and then tried it again, blocked again:
(discovery:20:32:PST)% mtr --report --report-cycles=5 --report-wide -s 1492 -L 5060 -P 5060 -u 45.32.4.66
Start: 2021-01-23T20:41:13-0800
HOST: discovery Loss% Snt Last Avg Best Wrst StDev
(discovery:20:41:PST)%
I went through all the other tests again and made sure they were consistent and they seemed to be. However, the traceroute probes seemed to introduce some weird behavior. The only thing that’s different between successive runs of MTR is the IP identification (ID) fields. Linux uses a common counter for UDP so if MTR is the only application using UDP the IDs will increment sequentially. Any other UDP application running in parallel will cause these IDs to start skipping numbers. hping3 allows the use of a random IP ID per packet, so CenturyLink maybe allowing special IP IDs seems to be a dead end since the random IP ID is the default for the tests I ran above.
So, I’m pretty confused. The only thing that results in inconsistent behavior is traceroute, which uses a TTL of 1 and then incrementing the TTLs until it reaches the destination. Maybe whatever filter CenturyLink is using does something special with low TTLs? I don’t know.
Regardless, even though we see inconsistent behavior it’s pretty clear that my CenturyLink DSL connection is filtering SIP INVITEs and that’s not good.
I am indeed using a CenturyLink-branded Zyxel C3000Z modem in bridge mode so it’s possible there’s some packet filter embedded into the firmware even though the PPP connection is terminated on my own equipment. Or, it could be filtered at the BRAS or DSLAM.
I haven’t really seen much on the Internet to confirm my findings (maybe nobody cares about SIP on a DSL connection?) and I don’t know if this also happens on CenturyLink’s FTTH/GPON offerings. The same DSL modem I am using is also used for the GPON service as well and also requires PPPoE, so maybe it’ll act the same.
Do any readers have the same problem? Or, different symptoms?
Well dang, did you ever get any where with this? I have set up a freepbx install and am also running into the same problem it seems. Please let me know!
Unfortunately not.
I’m continuing to route it through our Xfinity connection, which is pretty annoying because the CLink VDSL2 provides much less jitter, so it would be really nice to use that!
The other option would have to be just tunneling it through a VPS, which is a pretty sad solution.
It’s been a while so not sure you need any update. Short story: I’m hosting FreePBX server at home for my internal network (2 lines) + using outside SIP providers (voipms, others) and it all worked great, until I wanted to allow SIP clients from outside (internet) to log in. It didn’t work. Tcpdump didn’t show anything going thru (server is at DMZ, also tried forwarding specific port). Switched pjsip to listen on 5080 instead of the standard 5060 and dang! Everything works like a charm. So YES, Centurylink blocks incoming trafic on 5060 (not sure just SIP or anything). Had to change settings on my internal network SIP gateways to match the 5080 port and everything’s just fine. I’ll try to contact Centurylink for that, ideally if they could open 5060.